前面提到了,要訓練ML就需要數據,而且是大量的數據,這些數據不僅要大、更要多樣!
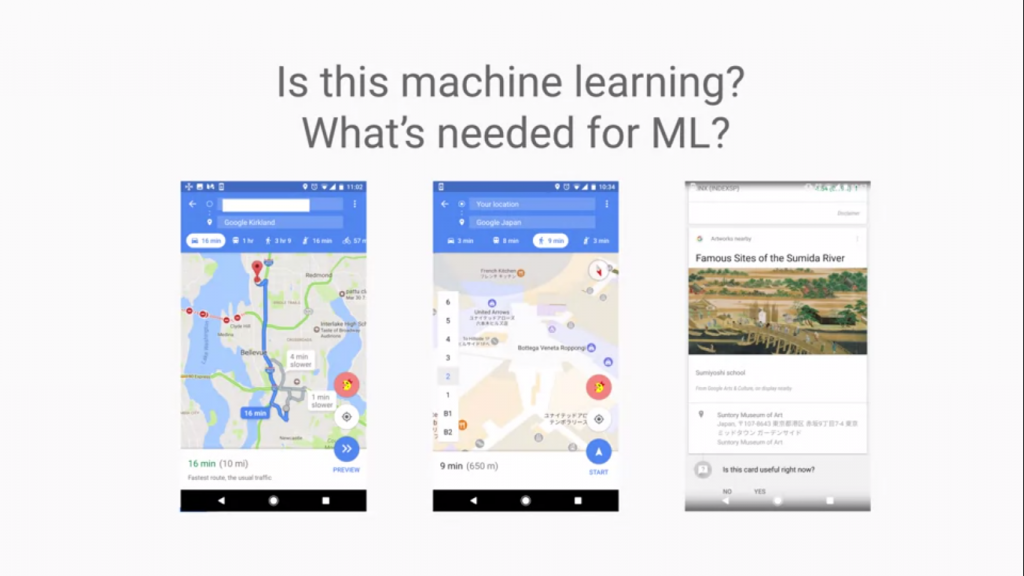
看到這張圖了嗎?左邊第一個是GoogleMaps的經典應用,搜尋地點以及找到導航最佳路線,
在掌握地方數據之後(例如:橋有沒有開放通行),我們可以輕易的編寫程式,達到效果。
而且我們需要掌握的數據量也不是那麼的大。所以在這裡我們如果用傳統的編程來解決問題,
不會有太大的問題
中間是Google地圖竟然知道使用者在打樓的第幾層樓,這也是MachineLearning嗎?
當然有很多方法來判斷使用者在第幾樓,不管是利用氣壓、GPS、歷史的定位紀錄......等。
很明顯這不是一套簡單的邏輯。
而我們學習MachineLearning就是要避免編寫邏輯(寫程式)(在白話一點寫If-Else)來解決問題,
來看看左邊的圖吧!有看到嗎,這位使用者人剛好在日本,並且使用者對歷史、文化...等有興趣。
Google Maps自己推薦了有該地點的歷史、文化的文章給使用者,這就是Machine Learning。
只有通過機器學習才能實現地圖服務的個性化。
Machine Learning的魅力就在這裡,對每個用戶個性化、客製化的服務。
從左邊的轉變到右邊的轉變是什麼,
你可能會認為機器學習是一種在中間做事的方法,能夠獲取您碰巧擁有的數據,並培訓機器學習模型。但是,將機器學習視為一種在正確的方式上獲得各種事物的方法。(我把它Google Translate成中文之後還是看超久~)
這句話想了有點久才完全懂它,我認為它的意思應該是要表達我們不應該看手上的數據可以發展什麼ML model
,而是要看我們要發展什麼ML model去蒐集我們應該要有的數據!
有看到最右邊功能最下面的問題嗎?
這個資訊實用嗎?
這裡就是使用者在進行反饋的地方,也就是使用者的滿意度,也就是由使用者直接告訴ML model,
你需不需要被修改(訓練)。
當我們進入複雜模型和各種調整模型以獲得更好和更好性能的方法時,很容易忽視關鍵點。數據每次都佔了優勢。
因此,如果在更多數據和更複雜的模型之間進行選擇,請花費精力收集更多數據。而且我的意思是收集的不僅僅是更多的數量,也包括更多的變化。
Google告訴我們比起訓練一個複雜的ML model,不如從數據下手吧!
這就是發展ML多年,世界第一的AI公司得出的結論!
數據就是一切。
幾年前Google發現自己的搜尋引擎下出現了一些有趣的問題,例如:基西米的活龍蝦、我附近的素食甜甜圈,
在那個ML還沒倒入的情況下,Google可以選擇暫時先用編寫code的方式來解決,
不過這絕對不是一個上上策,畢竟過了不久,這個搜尋引擎就會變得笨重(前面好幾篇都在講這個了XD)
今天的問題是,一位使用者想要找到最近咖啡廳,那麼我們應該怎麼給他答案呢,
或者換個問法,機器學習在學習時需要答案(label),機器才知道自己是否正確,那麼我們怎麼給他答案呢?
人為分析?不,我們透過回饋讓用戶直接告訴機器答案,
而使用戶的滿意度最佳化,正是機器在做的事情。
最近的咖啡廳的問題,一位用戶要求我們給他最近的咖啡廳,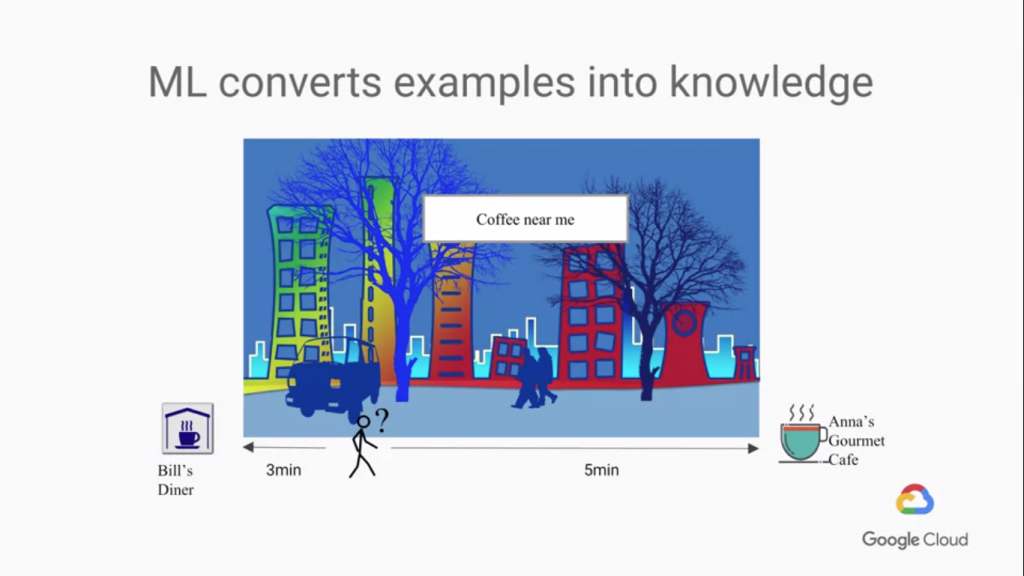
我們要如何給他呢?有兩種選擇,一個是左邊的咖啡廳,一個是右邊的,
各位可以看到兩個路程不同,但是對於使用者來說,左邊的咖啡廳就是正確答案嗎?
或許該使用者可以接受的"最近"的距離在十分鐘以下,那麼兩間咖啡廳都在合格範圍內,
那麼這時,咖啡廳的距離還會是我們考慮的重點嗎?還是CP值、又或者是用餐環境?
我們不猜測,Google表示,我們要透過客戶回饋來告訴我們model是否做出了正確的預測!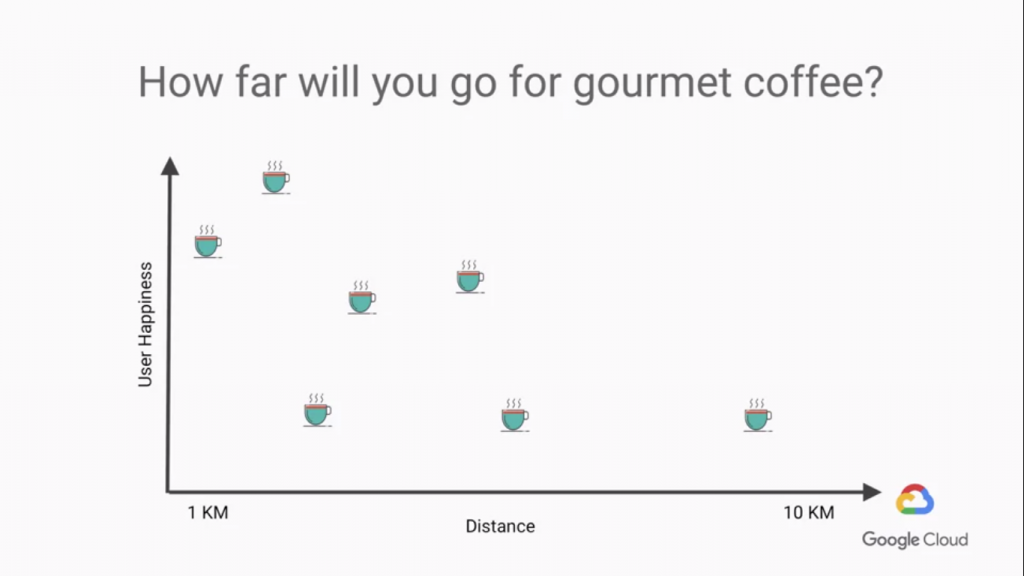
得到了這些數據,我們就可以讓model去學囉!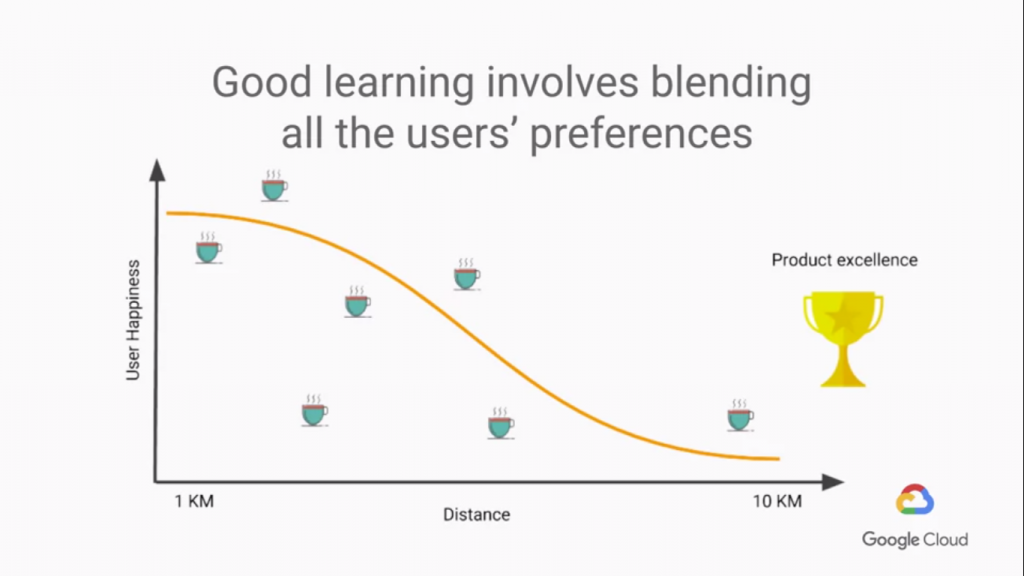
但這在剛開始發展機器學習來說資料是個關鍵,在還沒有資料之前就沒辦法Train model
沒有model就沒有反饋,沒有反饋就沒有資料,沒有資料就不能train......
這樣一直循環,難道公司沒辦法發展AI了嗎?不,Google在剛開始使用了啟發的方法來得到數據。
所謂的啟發就是類似,使用者來問Google,但是Google隨便回個答案給使用者而已,
請注意隨便是指"在合理的範疇下"(總不可能你在高雄問"最近的咖啡廳",結果把你報去台北)
然後再透過反饋,得到數據(使用者滿意度!)來進行Training,
Google使用啟發的方法來給使用這答案並不是要戳使用者,在拿到足夠的數據時,
Google就拋棄了這個方法!
在蒐集巨量的數據後,進行Train,就會得到最後一張圖的結果,
你的model會混合了所有使用者的偏好!所有的預測將會根據不同的使用者資料有不同的輸出!也就是客製化的答案了。
-我是Dim,第六天晚安。有發現嗎?數據真的很重要喔!~Google其實整個課程一直在講~


 iThome鐵人賽
iThome鐵人賽